INTRODUCTION
Discussing video editing with AI benefits from first outlining key terminology relevant to a wide range of AI systems. For example, the term cognitive architecture (CA) refers to computational frameworks designed to enable the simulation of human cognition. Drawing from research in psychology, neuroscience and AI, CA’s operate based on theories about human reasoning, problem-solving and learning. They function as blueprints for the construction of digital systems, by specifying fixed structures and interactions among those structures. Examples of CAs include ACT-R, Soar, and CLARION, which have been used to study various cognitive tasks and build intelligent agents – artificial entities that work autonomously (1) (2).
A CA can be integrated with deep learning (DL). DL is a subset of machine learning used in image and speech recognition, natural language processing and autonomous systems, among other computational fields (3). It involves artificial neural networks (NN), often called deep NNs. These are designed to learn hierarchical representations of data; as data passes through the network, it can recognise complex patterns and learn intricate structures.
Artificial neural networks have been applied to a wide range of problems, from speech recognition to ‘prediction of protein secondary structure’, classification of cancers and gene prediction (4). A NN includes a stack of layers with nodes (or “neurons”), as well as input space and output space. The nodes are interconnected, forming a dynamic graph. Throughout the learning period, the NN keeps updating the weight of interconnected nodes, to better fit the training data.
This process enables a mathematical calculation called embedding: to generate embeddings from input data means to derive a numerical representation of a piece of data from a trained NN, given its input space and its previous state. Embeddings are usually produced as a vector map. They can be used in many tasks performed through the graph, including classification, clustering, link prediction and visualisation (5).
Neural network mechanisms have been greatly refined with a deep learning architecture called transformer, developed by Google. This architecture applies an “attention mechanism” drawn from previous models such as recurrent neural networks (RNNs). RNNs can process data sequences but they cannot retain information over long sequences – a temporal problem seen in language translation and speech recognition. A transformer enables the AI system to focus on specific parts of the input data while capturing dependencies over long data sequences. Transformers revolutionised natural language processing, powering applications such as machine translation, text summarisation and language understanding (6).
Yet another important notion in contemporary AI is the one of large language model (LLM). Trained on large amounts of data, LLMs can perform a wide range of tasks, such as understanding and generating natural language. Available systems are accessible to the public through interfaces like Open AI’s Chat GPT-3 and GPT-4 (Generative Pre-trained Transformers), which garnered Microsoft’s support (7). Most LLMs after 2017 employ transformer networks.
LLMs can produce data streams that correlate different modalities – audio signals, video frames or metadata, to name a few (8). Deep learning AI systems have been successfully applied in professional audio-visual production, using neural networks to continuously infer data sequences for direct media generation or search (9). Cognitive architectures proposed prior to transformer architectures and the current DL ecosystem entail characteristics that can equally enhance the design of current generative systems.
In this essay we tackle the development of video sequences through LLMs, and propose a specialised transformer-based system that implements design guidelines from existing cognitive AI architectures. Our research focuses on the modelling of video sequences – simply called video editing here – and we will present a working implementation that edits arbitrary video datasets.
Our results rely on computing the embeddings of an initial corpus of clips. We use two trained models, connected through natural language: a vision-transformer (ViT) for one-shot image description, and a GPT-J-6B language model for reasoning, contextualisation and text subtitles. Integrating several AI-driven processes advances the current research in automated video sequence editing. To evaluate our approach, we develop a stream of natural language from frame descriptions and we establish mechanics to search and select from the dataset.
The system builds upon existing retrieval paradigms: the current video induces the next one based on semantic constructs (Potapov et al. proposed this (10)) produced by an artificial cognitive architecture system (Choi proposed this (11)). Once we use LLMs, natural language works efficiently in searches by description, matching and context across different data structures (12). Matching modalities is a starting point for the organisation of elements such as samples from a video dataset following a natural language stream, at specific variability rates. Also, the discourse capabilities of LLMs are admirable when set to infer in a loop, and merged with image representations; film professionals and audio-visual practitioners in general might know how that can be advantageous (13).
TYPES OF COGNITIVE ARCHITECTURES: HISTORICAL CONTEXT
CAs specify the structures and functions of cognitive systems as well as the interaction between them (14). They explore a multidisciplinary goal and hypothesis: to effectively define and build a simulation of observable structures of cognition, such as patterns in the human brain, or behaviours in a context environment (15). Researchers in the field attempt to specify a computational structure for intelligent behaviour (16). Using psychological evidence and computer models, they aim to find an infrastructure for general intelligence (17).
CAs implement theories about essential representations and mechanisms (18), including:
– Compatibilities of big data analysis and analysis of brain impulses.
– Prediction and active inference at variable clock rates with temporal changes to weights.
– Long-time continuous learning and reasoning over known possibility sets.
– Value systems and engines for motivation depending on, e.g. valence, arousal and dominance restrictions and differentiations.
– Action-reaction through boundary definers of self-contained systems within controlled environments.
To what extent can a machine simulate human cognition, which is inherently embodied, context-dependent, and changes over time? For at least fifty years, researchers have been modeling AI systems as cognitive architectures (CAs), during which time computing units have evolved dramatically. Both the limitations of computation and scientific understanding of cognition in natural systems have progressed significantly (19). Today, new insights from cognitive science, psychology, and neuroscience continue to reveal complexities and abstractions within the human brain, such as the nuanced role of natural language communication, including the use of embedded vector representations. A key objective has been to determine whether higher-level cognition relies on a unified system, or if distinct systems handle specific functions, such as vision, hearing, or movement, particularly in studies of knowledge representation and production systems (20). Advances in processing power, a deeper understanding of the brain and strategic design choices have led to the development of several domain-general CAs, including those mentioned in the introduction: ACT-R (Adaptive Control of Thought – Rational), Soar, and ICARUS.
Many other cognitive architectures (CAs) will appear throughout this manuscript, showcasing their diverse design choices and task specialisations. These architectures exemplify various approaches to identifiable subsystems of human brain function and intelligence, such as short-term and long-term memory modules. Most literature focuses on digital computations performed in CA simulations, with structures distributed across different physical processing units. Researchers have demonstrated the effectiveness of implementing neural networks (NNs) within CAs, as seen in connectionist approaches like the CA CLARION, which captures significant abstractions based on brain processing through layered structures (21).
Figure 1 displays a simplified taxonomy of CAs, from a comparative study showing their diverging ‘memory‘ and ‘learning‘ modules and processes.

Figure 1: A simplified taxonomy for cognitive architectures, retrieved from Asselman et al., 2015.
Early examples of cognitive architectures (CAs) include the General Problem Solver (GPS), a computer program developed by H. Simon, J. Shaw and A. Newell in 1957. This program explores the psychology of human thinking and proposes a theory to explain why some individuals attempt to solve specific simple formal problems. GPS provides a general theory of cognition that remains independent of particular phenomena, allowing modellers to add representations for specific tasks. Researchers then simulate the architecture on a computer to produce behaviour, which can be compared to human behavior in the same tasks (22).
In their early work, Frixione et al. identified five possible approaches to the problem of Knowledge Representation in Cognitive Science (23):
– Compositional symbolic approaches;
– Local non-compositional approaches;
– Distributed non compositional approaches;
– Cognitive sub-symbolic approaches;
– Neural sub-symbolic approaches.
Soar can be considered a direct successor to GPS, sharing the assumption that mechanisms for problem solving are key to human cognition and intelligence. Soar is a general problem-solving architecture with a rule-based memory developed from the GPS paradigm (24). The authors propose a study on the mechanisms necessary for intelligent behaviour, including search-intensive tasks, knowledge-intensive tasks and algorithmic tasks, to form a general cognitive architecture (25).
At that time, they posited that general learning mechanisms for a performance system would need to exhibit the following properties:
– Task generality
– Knowledge generality
– Aspect generality
To explore the validity of a cognitive architecture, it is worthwhile to examine a particularly successful example of the functional approach: TacAir-Soar, which models a fighter pilot and is built using the Soar architecture (26). The goal is to create multiple simulated pilots that can participate in large-scale warfare simulations, where the models operate alongside human pilots and other personnel. The main criterion for success is whether the models behave like real pilots, thereby contributing to an authentic experience for the humans involved in that specific simulation.
Other architectures do not regard problem solving as a fundamental mechanism but rather as a component of specific models pertaining to particular problem-solving situations (27). For example, the ACT-R architecture, along with its predecessors, draws inspiration from cognitive psychology (28). Just as GPS served as a foundation for Soar, the Human Associative Memory (HAM) model was a precursor to Adaptive Control of Thought (ACT-R) (29). ACT-R is a cognitive architecture featuring a core production system that includes a pattern matcher, which operates on memory and perceptual-motor modules via buffers (30). Building upon the HAM model, John Anderson developed the ACT-R theory through several iterations, culminating in the first major version, ACT* (31).
Later in the post-internet era, the Learning Intelligent Distribution Agent (LIDA) was proposed as an intelligent, autonomous software agent designed to assist personnel in the US Navy (32). The LIDA architecture is an extension of the IDA model, funded by the Office of Naval Research and other Navy sources. LIDA is largely based on Baars’ Global Workspace Theory (GWT) which broadens the focus of cognitive architecture design to encompass a theory of consciousness (33). This theory has, at various points, become the most widely accepted psychological and neurobiological framework for understanding consciousness (34).
Implementations of these cognitive architectures demonstrate functional properties of intelligence through observation and seek to establish general methods for automating task solutions, supported by various specialised procedures or modules.

Figure 2: The Global Workspace Theory metaphor, extracted from Bernard J Baars, 2005.
The rise of neural networks in computing and AI research has developed largely as a distinct field from cognitive architectures. Even prior to advancements like Graphical Processing Units (GPU) and modern machine learning frameworks, CAs successfully implemented NNs and established connectionist paradigms, functioning as networks of diverse processing modules. One example, CLARION, represents a hybrid, dual-process CA that differentiates between explicit and implicit cognitive processes (35). On a similar level, the CA OpenCog implements NNs as well, which can develop to be a system encompassing many different AI models to be used within the same ecosystem, the authors pose CogPrime as a draft architecture for artificial general intelligence (36).
In summary, CAs are certainly a good a candidate for video editing systems, and well-suited to integrate with LLMs or other generative models, as we will show ahead.
SPECIALISED COGNITIVE ARCHITECTURES
In the past two decades, various CAs have been developed with targeted action applications, rather than purely generalised problem-solving, though these applications might still contribute to more general solutions. AI researchers have begun designing CAs to address specific tasks, such as understanding video frames by classifying and detecting anomalies in defined environments.
For example, Doulamis et al. propose a self-configurable CA for monitoring video data in manufacturing, which utilises weakly supervised learning algorithms and self-adaptation strategies to analyse visually observable processes (37). Their advanced architecture, known as the Self-Configurable Cognitive Video Supervision system (SCOVIS), incorporates attention models that focus on regions of interest (ROIs) and objects of interest (OOIs) in static images and video sequences. SCOVIS also supports camera coordination across a network. Principe describes a similar CA developed for object recognition in video, aiming to abstract computational principles from the animal visual system to interpret video images (38).
Li et al. present a novel CA that understands the content of raw videos in terms of objects without using labels (39), achieving three objectives:
– Decomposing raw frames into objects by exploiting foveal vision and memory.
– Describing the world by projecting objects onto an internal canvas.
– Extracting relevant objects from the canvas by analysing the causal relationship between objects and rewards.
Beyond data processing and its patterns, this specialised example (vision and raw image or video frames) clearly indicates a biologically inspired design for the structure of the CA. Further research on this topic can be found in the proceedings of the Annual Meeting of the BICA (Biologically Inspired Cognitive Architectures) (40).
APPLICATION IN GAME ENVIRONMENTS
The application of cognitive architectures has not only been notable in manufacturing environments, but also directly within video game engines. By applying a CA in an ecosystem with its own rules, players, and environments, automation can either encompass all human actions or exist alongside the player, facilitating non-linear dynamics.
Li et al. propose an architecture for frame-oriented reinforcement learning – a type of machine learning that focuses on learning optimal actions based on individual frames or images. This system is designed to understand the content of raw frames and derive meaningful representations (41). The authors demonstrate its capability to recognise and classify characters within Super Mario Bros. The system is modelled to:
– Extract information from the environment by exploiting unsupervised learning (learning from unlabelled data) and reinforcement learning (learning through trial and error, where successful actions receive positive feedback known as rewards).
– Understand the content of a raw frame.
– Exploit foveal vision strategies (focusing on specific details, similar to human vision) analogous to the human visual system.
– Collect new training data subsets (smaller data portions) automatically to learn new objects without forgetting previous ones.
In the same realm, the cognitive architecture OpenCog has also been applied to virtual characters, such as dogs in the OpenCogBot project, which features an interactive question-answering environment. These virtual dogs demonstrate the ability to learn new behaviours through imitation and reinforcement, showcasing the potential of CAs in enhancing the realism and interactivity of virtual characters (42).

Figure 3: Screenshot of OpenCogBot-controlled virtual dog, retrieved from Goertzel et al., 2010.
APPLICATION IN IMAGE AND MUSIC SIGNALS
Cognitive architectures (CAs) have also been developed in the context of computational creativity, demonstrating creative behaviour in specific data patterns such as audio or image frames. Li et al. introduce a system that implements creative behaviour within a CA (43). The system draws from cognitive science and computational creativity, particularly the PSI model and the MicroPSI model (44). It can generate portraits starting from a subject’s snapshot, creating a set of basic styles during a training phase and proposing novel combinations of the input image. The implementation successfully demonstrates motivation in selecting subsequent parts of images based on the flow processes between memory modules.
Focusing on producing content with creative value can be achieved through imitation, which is extensively studied in the context of style transfer and deep neural networks (45). Modelling also extends to audio frames and music sequences, with the generation of music accomplished through the MusiCOG cognitive architecture (46). This CA is integrated with an interactive music composition application called ManuScore. In both examples, the CA systems encode inputs in useful ways for prediction, employing diverging design choices. The flow of information within the CA modules allows for the production of variations. In this case, the CA interoperates with secondary software that includes notation, facilitating an interaction loop between the human and the AI system.
Across various application scenarios and design guidelines, CA architectures consider both symbolic and subsymbolic levels, as well as connectionism through deep neural networks. Chella et al. discuss hybrid architectures where different processing modules coexist and cooperate in a principled manner (47).

Figure 4: Workflow used to place an input image on a Style Map, retrieved from Augello et al. 2013.
TRANSFORMER MODELS WITHIN COGNITIVE ARCHITECTURES
With the advent of neural networks (NNs) and deep learning (DL) models, cognitive architectures (CAs) are undergoing significant re-imagination. Many implementations now leverage specialised modules enabled by NNs for tasks such as one-shot reasoning (drawing accurate conclusions from minimal information), including image classification. In computer vision, convolutional neural networks (CNNs or ConvNets—networks designed to recognise patterns and spatial hierarchies in images) were dominant prior to the emergence of transformers, which have gained prominence recently (48). Transformers, based on an attention mechanism, are typically trained offline on large corpora. Their development facilitated the creation of large language models (LLMs) like GPT (49). It addressed challenges of recurrent neural networks (RNNs), which process data sequences but struggle to retain information over long sequences—a limitation known as the “forgetting problem” (50).
The Transformer architecture, built around a multi-head attention mechanism (allowing the model to focus on different parts of an input sequence simultaneously), is also effective for image data. Dosovitskiy et al. show that dependence on CNNs is not essential for applying attention to images (51). They demonstrate that a pure Transformer, applied directly to sequences of image patches, achieves high performance on image classification tasks when pre-trained on large datasets and tested on benchmarks like ImageNet, CIFAR-100 and VTAB. The vision-transformer (ViT) matches or exceeds state-of-the-art convolutional networks’ performance while requiring significantly fewer computational resources for training (52).
Transformers have also been adopted in cognitive architectures (CAs), retaining some of the structures from early systems. Laird et al. present a proposal for integrating CAs with transformers, featuring a long-term memory system (LTMs store information over extended periods) supported by a neural network itself (53). The authors identify potential capabilities for transformers within a CA, functioning as prediction engines to forecast future working memory states, including:
– Anomaly detection: identifying when a situation deviates from the routine.
– Action modelling: predicting the consequences of an action.
– World modelling: anticipating changes in world dynamics.
– Preparation: taking actions to influence an unexpected future.
Sun recently suggested that incorporating insights from human cognition and psychology, as embodied by a CA, can enhance the capabilities of these systems (54). He emphasises the significance of dual-process architecture (a framework distinguishing between automatic and controlled cognitive processes) and the hybrid neuro-symbolic approach (which combines neural networks with symbolic reasoning) in overcoming the limitations of current large language models.
Sumers et al. further propose a framework called cognitive architectures for language agents (55), aimed at addressing the need for more capable LLMs. They present a unified study of their integration with production systems (computational models that use rules to determine actions). They characterise language agents as a class of LLMs capable of demonstrating common-sense reasoning during conversations or when functioning independently. To enhance LLMs, they propose methods such as feedback (the process of using the output to inform and improve future responses) and recursion (the ability to apply a process repeatedly, allowing for more complex reasoning). This includes techniques like prompt chaining (linking multiple prompts to build context and improve response accuracy) and integrating external resources via search (utilising real-time information from databases or the internet to supplement knowledge).
AI SYSTEMS FOR VIDEO EDITING
In video editing and post-production, automation has extended to both multi-track editing—which layers multiple video and audio tracks in a time-based sequence—and algorithmic approaches, which apply data-driven techniques rather than relying solely on a timeline. With advances in deep learning and artificial intelligence (AI), these automated approaches have introduced new capabilities. Trained models can now restore old footage (e.g., by removing noise or improving resolution), conduct content-based searches (such as locating specific scenes), and predict image content (for example, generating missing frames), tasks that previously required manual adjustments. Additionally, by linking these models with recording data, AI-driven analysis and inference can enhance or even replace traditional methods like segmentation (56), and create new options, such as AI-guided segmentation using large language models (LLMs).
Professional video editing and manipulation involve various tasks, such as adjusting aspect ratios, resizing, and reshaping frames (57). AI systems now add new possibilities, including video summarisation, frame colourisation, and special effects. In film and media, workflows are increasingly enhanced by AI, particularly through the concept of a “virtual camera”—a digital stand-in for a real camera.
AI systems using virtual camera views include:
– Neural Radiance Fields, which create realistic 3D scenes (58).
– Depth estimation, used to gauge distances between objects in a scene.
– 3D point clouds, helpful for constructing and editing 3D environments (59).
Signal processing and understanding of video frames is a process that evolved with the human element at the forefront throughout the entire production chain, incorporating AI systems such as LLMs to assist in specific tasks. Many roles in film production, from camera crew to colour grading, have retained their distinct specialisations, which are often conceptual and based on the expertise of the individuals involved.
In 1994, Tonomura et al. proposed a simplified video computing process, at a time when video was becoming an increasingly important medium, outlining structures still prevalent in today’s professional filmmaking practices (60). The authors envisioned possible visual interaction modes with computers informed by the roles humans play during shooting and editing, designing a system that:
– First analyses a video stream and automatically segments it into shots.
– Each shot is indexed using extracted features, which involves cataloguing and organising the footage based on identified characteristics.
– Detecting camera work information and identifying dominant colours within the shots, which can be used to convey specific moods or themes.
Still in the 1990s, Ueda & Miyatake proposed an approach to integrate image recognition technology into nonlinear (non-sequential) video editing systems. They discussed the results of a prototype with five functions for users:
– Automatic scene separation during disk recording, which segments footage into distinct scenes automatically while recording, simplifying the editing process.
– Tree structure story editing, a method that organises scenes hierarchically, allowing editors to view and manipulate story elements in branching paths for easy narrative structuring.
– Quick simultaneous shot reviews, enabling editors to view multiple shots at once for efficient comparison and selection.
– Film metaphor interface, a user interface that mimics traditional film editing tools, making digital editing more intuitive.
– Integrated multimedia information management, which helps users organise and retrieve various types of media, such as video, audio, and text, within the editing system.
With the development of the desktop computer in that decade, Nack and Parkes presented a specific model of the editing process and outlined the basis for strategies of humour as a case study (62). The authors described AUTEUR – AI utilities for thematic film editing using context understanding and editing rules. – which relied on a model of editing based on a knowledge elicitation exercise that involved studying and interviewing editors in their work environments (63). Figure 5 summarises the system (64).
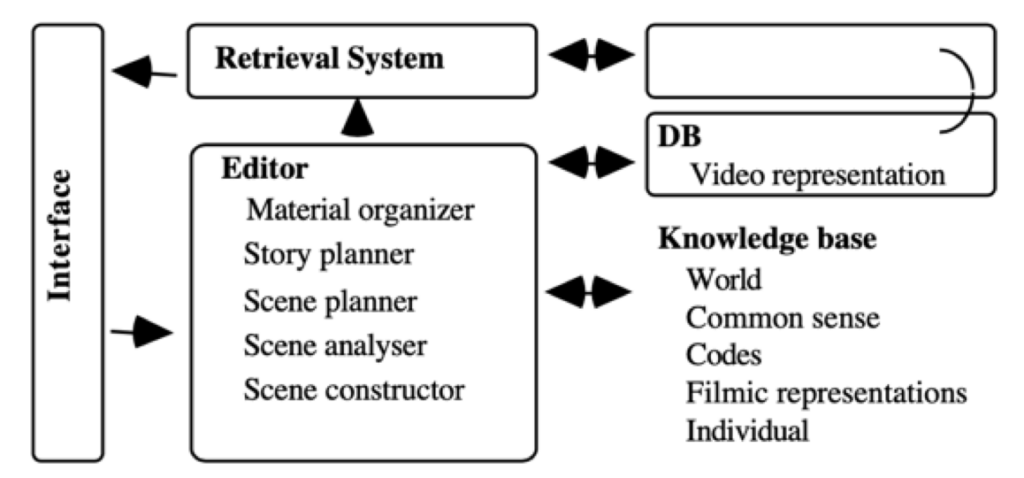
Figure 5: Architecture diagram of AUTEUR system, retrieved from Frank Nack et al., 1995.
Knowledge can be derived from physical environments by video cameras, recording and editing mechanisms can be developed with real-time incoming footage and real-time processing of that footage. There is virtual representation of the cinema camera to the AI model, and there is also output control for camera movements, these may include editing techniques inscribed in the system. If an AI system would control flight modes for film it would have to at least represent in itself modes of shooting, so conventional procedures in filming can be respected.
Aerts et al. introduce the CAMETRON project that aims to developing an almost fully automated system to produce video recordings of events such as lectures, sports games or musical performances (65). The system includes components such as intelligent Pan-Tilt-Zoom cameras (which can automatically adjust their position and zoom to focus on subjects) and UAVs (Unmanned Aerial Vehicles) that function as camera assistants.
TRANSFORMER MODELS IN VIDEO EDITING
Vasconcelos and Lippman presented an early approach using a Bayesian model architecture — a statistical model that updates probabilities based on evidence — for content characterisation, analysing its potential for accessing and browsing video databases (66). This model demonstrated the ability to browse video databases semantically, which is relevant today with LLMs that use natural language interfaces for search. The video editing process often begins in cinematography, with shooting considered in relation to editing mechanics, making camera control crucial throughout film and audiovisual production.
Within neural networks and cognitive architectures, concepts for image data are deconstructed by models; the graphs compute through their layers, processing data to achieve desired outcomes. Today, transformer models assist in video editing, using natural language guidance and being trained on textual instructions for specific tasks. The video editing software and cloud service Kapwig provides AI-powered tools, such as video trimming using a text-based editor from transcripts (67).
Models of video editing not only consider the roles of the human editor and cinematographer, but also incorporate cultural aspects by focusing on learning from large datasets of images and texts.
In 2024, Wang et al. propose an LLM-powered video editing software and raise a study on a system (68) that allows for:
– Video retrieval
– Footage overviewing
– Idea brainstorming
– Storyboarding
– Clip trimming
– Title generator
In this approach, the editor can engage in a conversation with the LLM, which assists in editing the video by offering interaction through natural language prompts.
When exploring the use of transformers in video editing, one promising approach is applying language-guided transformations. This method enables techniques like style transfer, which allows for the alteration of a video’s visual characteristics by transferring the style of one video to another. A key technique in this process is the diffusion model, which gradually modifies an image or video by adding noise and then removing it, enabling precise control over the transformation. MaskINT, a system built around this model, uses natural language guidance to direct the transformation of videos, facilitating tasks such as style transfer and content modification (69).
OUR SYSTEM: GOALS AND METHODS
Continuously generating embeddings from trained models and measuring distances between these embeddings allows a model to represent diverse input data and find similarities between different pieces. In this context, “distances” refer to measurements of similarity between data points, which are represented as vectors in high-dimensional space. This approach enables the model to identify relationships between video elements based on their similarity. A common technique for handling multimodal data (e.g., video and text) is to establish a shared natural language framework, allowing models to translate specific types of content into text. Training transformers to work with embeddings in this way has proven effective across video and music applications (70).
This research addresses the challenge of automated video sequence editing by using transformers as “one-shot reasoning systems”, which make decisions based on minimal input. This approach relies on embedded features — such as objects, colours and scene types — extracted using a vision-transformer (ViT), pre-trained on large datasets. These features define both the sequence order and duration of video elements, enabling the production of coherent video sequences without human input. To support this, our system generates both image and text embeddings, which include confidence levels indicating how accurately each embedding represents key features of the content.
The ‘confidence’ reflects the semantic similarity between embeddings. After training, the model can detect similar features in new, unlabeled video frames by recognising patterns that match those learned from the labelled data. This labelling process forms the foundation for the model’s ability to automatically detect and define these visual characteristics.
Through the experiences conducted, we reflect on the human editor’s intuitive ability to select the next sequence when creating a montage. This ability often relies on similarity, or, in other words, on memory systems that favour the closest pair to lived experience. We also recognise that this research could benefit from integrating vision encoding and embedding techniques, enabling montage creation by both visual and semantic similarity. This approach shows considerable potential, particularly when working with large video datasets.
To develop this system, we adopted a practice-based methodology (71). We tested our hypothesis by observing the resulting videos, using a small video dataset to accurately identify the undertaken sequencing.
We consider the research successful when the system functions as a tool that disrupts or rearranges the content in professional editing contexts, aiding the editor in generating new ideas or perspectives. The system we implemented can analyse the content of related videos and automatically suggest sequences that offer fresh insights, helping the practitioner reassess the current edit.
Nevertheless, our approach may lead to continuous failure if the original image-text correspondence does not align with the intended meaning or human interpretation. We regard this as acceptable behaviour in experimental contexts. In fact, it could also inspire new creative approaches.
The experiments aim to produce finished video sequences from an arbitrary video dataset using an input prompt, with the following features:
– Present-future correspondence across 10 to 20 elements: This involves aligning video content that connects present actions or scenes with potential future developments, using 10 to 20 key elements to establish this link.
– Clip-based narratives for subtitles: Subtitles are generated from specific video clips, with each clip contributing to a narrative or story that enhances the viewer’s understanding of the video content.
– Varying length based on confidence values inherent to the models: The length of the generated sequences adjusts according to the model’s confidence in its predictions. Sequences generated with higher confidence are longer, while those with lower confidence are shorter.
Our system is a language-based video sequencer. It focuses on three key aspects:
– Production of a sequence of clips sampled from a given video dataset (distribution), where “distribution” refers to the variety and range of video content within the dataset. The clips are ordered according to the semantic meaning derived from a vision-transformer (ViT) for each clip, with the ViT pre-trained on ImageNet21k to extract meaningful features from each video frame (72).
– Definition of the duration of each clip, based on the confidence attributed by the ViT to each label, determining how strongly the model associates each clip with its label.
– Production of a text-based narrative for subtitling, generated by GPT-J-6B, a 6 billion-parameter transformer trained on the Pile dataset, a large text corpus containing diverse publicly available sources like books and websites (73). The narrative is created when the system is prompted with the set of labels derived from the video clips.

Figure 6: Flow diagram from video dataset input to video sequence output.
WORKING OUTCOMES
We conducted a series of experiments using a small open domain video dataset, consisting of 40 clips selected from the Internet. Open domain refers to a dataset that covers a broad range of topics or content types, without being restricted to a specific field or category. The goal was to develop an algorithm that predicts the most likely next video based on an input prompt. After making a couple of random selections (1% of the dataset), it returns to the video sequence that is most probable given the context.
From this algorithm, we generate an embedding space that represents all the videos in the dataset, where each video is encoded by its first and middle frames. This allows the model to capture key visual characteristics of the video at different points in time. The natural language descriptions provided by a vision-transformer (ViT) are used to generate semantic representations of each video, which are grouped into clusters of four frames based on similarity. These clusters are then stored as embeddings in the AI system for further analysis.
Similarity measures are applied to explore the relationships between the videos, where each video is considered a data point in the high-dimensional space. This approach is akin to memory recall, as the system finds connections between the most relatable data points (the ones closest to the input) and those that are more distant, enabling the creation of arcs of reasoning. By searching through these data points, the model can explore the video space from the most relevant to the furthest removed elements.
Figure 7 illustrates a randomiser tool, which initiates video sequences based on the initial prompt “prayer” and randomly selects related videos from the dataset, demonstrating how the system identifies connections between video elements. Thematic similarity appears as a concurrent church drone shot, showcasing the tool’s capability to recognise content alignment.

Figure 7: 20 video sequence thumbnail strip with “prayer” input prompt.
For each keyframe, we generate a 200-character narrative description using GPT-J-6B, a large language model that produces natural language outputs based on ViT labels — semantic tags assigned to each frame by the vision-transformer. These help to capture and describe the main content and themes of the video. These narratives are then aggregated into full sentences and paragraphs, providing contextualised subtitles for each video segment.
To document this process, we allow the system to continue selecting elements after the initial “prayer” prompt, creating a sequence that progressively diverges from the starting theme over 10 selections. In Video 1 the sequence segment is set to approximately 13 seconds, with two subtitle calls per segment, a format that can be quantised to meet standardised time lengths.
Additionally, we developed a time-scaling system (illustrated in Figure 6) to adjust playback duration according to ViT label confidence (a scalar measure that reflects how accurately each label represents the content in each segment). Given the varying lengths of videos in the dataset – which average 32.35 seconds in the 40-video collection – the system applies a scalar to modify playback time according to each segment’s confidence level (see Video 2), even allowing for looping if needed. For consistency in the demonstration, we started by cropping each of the 10 selected videos to the same length.
Video 1: Sequence of 10 videos with same length.
Video 2: Sequence of 10 videos with length from ViT confidence.
The system was developed across two independent computer units with:
– NVIDIA RTX 3070/3090 graphics cards (for GPU computing with CUDA support; intensive computing tasks are significantly faster once parallel processing work is offloaded to the GPU).
– GGML tensor library (for deep learning processing) (74)
– ImGUI (Immediate Mode Graphical User Interface), a library for developing user interfaces).
– All run on Windows 11, with FFMPEG encoders for video processing.
The system deploys trained models, specifically the ViT vision-transformer (75) and GPT-J-6B transformer, which are built to operate on CPUs instead of GPUs, implying lower power consumption. Additionally, we tested the use of prediction lists, where models communicate anticipated outcomes, over HTTP via ethernet. This setup, using TP-Link Archer AC1900 and TL-SG108 (LAN), enables efficient data exchange between devices, supporting research on separate computing instances, such as those used for graphical sequence tasks.
The GUI interface was developed to display key variables for the sequence outputs illustrated in Figure 8. It includes:
– A 10×10 trainable matrix grid visually representing all keyframes from the video dataset, with colour coding to indicate ViT confidence levels, ranging from ‘0’ (blue) to ‘1’ (red).
– A set of callback functions (predefined response triggers) for inspecting and processing system operations.
– A visualisation of the prediction list, showing attributes for each video dataset.

Figure 8: Lightweight GUI for human input and monitoring of the video dataset.
DISCUSSION
Interest in the audiovisual and film industries often centres on using automatic systems for recommendations. Employing automatic sequencing and editing systems as a tool for professional editors or other post-production roles can be valuable for brainstorming. Adjusting such AI systems enables practitioners to explore metacreation, where the algorithm influences the final creative work (76). LLMs and other trained generative models can be used for video editing when a common representation is achieved across separate models with distinct functions (77).
Our research views video editing as a sequence-based process, where we developed an initial but complete AI processing chain from video dataset input to finalised video sequence output, utilising open-source technologies and testing with publicly available videos. It is now common practice to search through embedding representations to recommend semantically relevant content across various video tasks. This research implements a method for achieving semantic consistency across timelines using natural language, enabling the design of trajectories and further computations within embeddings that mirror real editing behaviours.
Prior to this research, other approaches to video editing focused on transforming an input video into something different through AI guidance (video-to-video) rather than sequencing distinct elements (78). We leverage the reasoning capabilities of Transformers, demonstrated in applications like GPT-powered customer service, as the basis for montage and future element selection. This approach provides mechanisms that allow practitioners to engage with sequencing methodologies interactively (79).
Our literature review identifies several valuable use cases where conversational agents (interactive AI systems) are applied in video analysis and image generation, informing our approach to processing video signals. Transformer-based systems can benefit from the memory flows and storage capabilities of conversational agents within a larger system, enabling the modelling of useful representations from video data (80).
The outcomes of this research are framed within the broader context of video editing systems and AI, as explored in the AI conversational agent domain (81). Here, AI systems act as processing nodes, where we define behaviours and working modules that interact based on specific tasks or natural phenomena, such as constructs of long-term and short-term memory, recursive thinking, and pattern recognition (82).
The proposed system can be developed to accept incoming video feeds, write data to disk, and display text on screen without relying on traditional subtitles. Leveraging the performance of contextualising video frames with GPT-J-6B, our results demonstrate the potential to create narrative arcs by defining search modes through keyframes and deriving natural language context from each video clip. The quick graph evaluation (a lightweight computation of node connections) on the CPU enables models to operate on timed triggers, allowing the system to function in complementary real-time applications, such as keyframing new video inputs.
We envision this design as part of a larger, interconnected AI ecosystem capable of producing meaningful representations of video datasets. By coordinating two trained transformers, our methodology also allows for indexing specific sections of larger video datasets through diverse frame selection processes. Image keyframes can be automatically generated from video datasets by using methods such as pixel activity thresholds, colour space analysis, or movement detection. This opens up further research possibilities.
The principles of editing and montage extend to the psychology behind the film experience— how images evoke emotions and sensations in viewers, and how sequences can be composed to enhance that impact (83). Editing also involves reasoning within a framework of similarity, where each subsequent state resembles the current one. This approach is particularly relevant for editing feature films and documentary films, which might span hours.
In this research, we explore reasoning through the sampling of a transformer model over time, reflecting the cognitive processes involved in video editing, with a focus on professional editing system architectures and work environments. The selection of elements from a set of videos can be viewed as the AI system’s current state, analogous to human thought, anchored in known input contexts and described through natural language, which evolves alongside the video frames.
By continuing to develop the system to encompass cognitive architecture processing flows, it becomes possible to formalise and study specific PSI theories — addressing not only cognitive processes but also motivational and emotional ones (84). This interdisciplinary approach can foster a more holistic understanding of montage as a cognitive process when shaped by AI. These representations can help convey specific intended messages within video edits and reveal cultural artefacts — underlying societal values, norms, or biases embedded in trained models.
CONCLUSION
This article details the design and implementation of a language-based transformer video editing system, positioned within cognitive architecture literature. Our proposal leverages ViT and GPT-J-6B models to generate embeddings — mathematical mappings that capture the semantic information of video datasets — which are applied to select video segments that logically follow one another.
The pipeline we developed structures this process by establishing a common natural language foundation for sequencing any chosen video dataset. It involves computing trajectories within an embedding space, meaning it creates paths of semantic relationships between data points. Additionally, it crafts narrative arcs — structured storylines — through subtitles and context for each video clip. Moreover, it determines the duration of each video segment based on AI-defined confidence levels, meaning the segment lengths are adjusted according to the model’s certainty in its interpretations.
Our research aligns with other AI applications in the film and audiovisual industries, focusing on video understanding and automatic sequencing. Through this work, we demonstrate that Transformers can effectively function as semantic similarity engines for sequencing video datasets using nonlinear timelines in natural language. Our approach centres on transition states, designed to support real-time text generation and image description. We document a series of experiments using a small 40-video dataset and prompt inputs, with sets of 10 or 20 videos sequenced based on semantic similarity, image-text alignment during transitions, subtitle generation, and the initial representation of the dataset.
Connecting trained models helps video sequences keep consistent meaning over a scale of seconds. Our AI system allows users to plan sequences by rearranging video clips and previewing the edited sequence based on text prompts. This method also makes it easy to organise collections of different shots using natural language and search.
ACKNOWLEDGEMENTS
Research leading to these results was conducted during the individual research grant 2020.07619.BD and financially supported by the Portuguese Foundation for Science and Technology (FCT) with host institution INESC-TEC, University of Porto and a visiting role at the UAL Creative Computing Institute.
REFERENCES AND NOTES
1. Niels Taatgen and John R Anderson, “The Past, Present and Future of Cognitive Architectures”, Topics in Cognitive Science 2, No. 4, pp. 693-704 (2010).
BACK
2. John E Laird and Paul S Rosenbloom, “The Evolution of the Soar Cognitive Architecture”, in Mind matters (New York: Psychology Press, 2014) pp. 1-50.
BACK
3. Y LeCun, B Boser, JS Denker, D Henderson, RE Howard W Hubbard and LD Jackel, “Backpropagation Applied to Handwritten Zip Code recognition”, Neural Computation 1, No. 4, pp. 541-551 (1989).
BACK
4. Anders Krogh, “What Are Artificial Neural Networks?”, Nature Biotechnology 26, No. 2, pp. 195-197 (2008).
BACK
5. H Chen, B Perozzi, R Al-Rfou and S Skiena, “A Tutorial on Network Embeddings”, arXiv preprint arXiv:1808.02590 (2018).
BACK
6. A Vaswani, N Shazeer, N Parmar, J Uszkoreit, L Jones, A Gomez, L Kaiser and I Polosukhin, “Attention Is All You Need”, NIPS – Advances in Neural Information Processing Systems Conference Proceedings (2017).
BACK
7. Definition extracted from <https://www.ibm.com/topics/large-language-models>, accessed 19 September 2024.
BACK
8. D Li, J Li, H Le, G Wang, S Savarese and S Hoi, “Lavis: A Library for Language-Vision Intelligence”, arXiv preprint arXiv:2209.09019 (2022).
BACK
9. L Engeln, N Long Le, M McGinity and R Groh, “Similarity Analysis of Visual Sketch-Based Search for Sounds” AM – International Audio Mostly Conference Proceedings (2021).
BACK
10. A Potapov, I Zhdanov, O Scherbakov, N Skorobogatko, H Latapie and E Fenoglio, “Semantic Image Retrieval by Uniting Deep Neural Networks and Cognitive Architectures”, Artificial General Intelligence – Lecture Notes in Computer Science() 10999, pp. 196–206 (Springer, 2018).
BACK
11. Dongkyu Choi, “On Using Generative Models in a Cognitive Architecture for Embodied Agents”, AAAI Symposium Proceedings 2, No. 1 (2023).
BACK
12. AS Koepke, AM Oncescu, JF Henriques, Z Akata and S Albanie, “Audio Retrieval with Natural Language Queries: A Benchmark Study”, Transactions on Multimedia 25, pp. 2675-2685 (IEEE,2022).
BACK
13. T Lin, Y Wang, X Liu and X Qiu, “A Survey of Transformers”, AI Open 3, pp. 111-132 (2022).
BACK
14. Valentin V Klimov and David J Kelley, eds., Biologically Inspired Cognitive Architectures 2021: Proceedings of the 12th Annual Meeting of the BICA Society (Springer Nature, 2022).
BACK
15. A Bubic, D Y Cramon and R Schubotz, “Prediction, Cognition and the Brain”, Frontiers in Human Neuroscience 4 (2010).
BACK
16. Allen Newell, Unified Theories of Cognition (Harvard Univ. Press, 1994).
BACK
17. Lin et al. [13.]
BACK
18. Taatgen and Anderson [1.]
BACK
19. ibid.
BACK
20. John R Anderson, The Architecture of Cognition (New York: Psychology Press, 2013).
BACK
21. S Helie, N Wilson and R Sun, “The Clarion Cognitive Architecture: A Tutorial”, Annual Meeting of the Cognitive Science Society Proceedings 30, No. 30 (2008).
BACK
22. Cecilia Heyes,“New Thinking: the Evolution of Human Cognition”, Philosophical Transactions of the Royal Society B 367, No. 1599, pp. 2091-2096 (2012).
BACK
23. M Frixione, G Spinelli and S Gaglio, “Symbols and Subsymbols for Representing Knowledge: a Catalogue Raisonne”, International Joint Conference on Artificial intelligence Proceedings 1, p. 3-7 (1989).
BACK
24. Laird, Rosenbloom and Newell [2.]
BACK
25. ibid.
BACK
26. R Jones, J Laird, and P Nielsen “Automated Intelligent Pilots for Combat Flight Simulation”, AI Magazine 20, No.1, pp. 27-27 (1999).
BACK
27. Heyes [22.]
BACK
28. Anderson [20.]
BACK
29. John R Anderson and Gordon H Bower, Human Associative Memory (Psychology Press, 2014).
BACK
30. Gerhard Weber, “ACT – Adaptive Control of Thought”, Encyclopedia of the Sciences of Learning (Boston: Springer, 2012).
BACK
31. Anderson [20.]
BACK
32. S Franklin and F G Patterson, “The LIDA Architecture: Adding New Modes of Learning to an Intelligent, Autonomous Software Agent”, IDPT – Integrated Design and Process Technology Conference Proceedings (2006).
BACK
33. S Franklin, T Madl, S D’Mello and J Snaider, “LIDA: A Systems-Level Architecture for Cognition, Emotion and Learning“, Transactions on Autonomous Mental Development 6, No. 1, pp. 19-41 (IEEE, 2013).
BACK
34. Bernard J Baars, “The Conscious Access Hypothesis: Origins and Recent Evidence”, Trends in Cognitive Sciences 6, No. 1, pp. 47-52 (2002).
BACK
35. Helie et al. [21.]
BACK
36. B Goertzel, C Pennachin and N Geisweiller, Engineering General Intelligence, Part 2: The CogPrime Architecture for Integrative, Embodied AGI (Springer, 2014).
BACK
37. A Doulamis, D Kosmopoulos, M Sardis and T Varvarigou, “An Architecture for a Self-Configurable Video Supervision”, ACM – Analysis and Retrieval of Events/Actions and Workflows in Video Streams Workshop Proceedings (2008).
BACK
38. Jose C Principe, “A Cognitive Architecture for Object Recognition in Video”, ICMLA – International Conference on Machine Learning and Applications Proceedings. (IEEE, 2020).
BACK
39. H Li , R Dou, A Keil and J C Principe, “A Self-Learning Cognitive Architecture Exploiting Causality from Rewards”, Neural Networks 150, pp. 274-292 (2022).
BACK
40. Klimov and Kelley [14.]
BACK
41. H Li, Y Ma, and J Principe, “Cognitive Architecture for Video Games”, IJCNN – International Joint Conference on Neural Network Proceedings (IEEE, 2020).
BACK
42. Z Cai, B Goertzel and N Geisweiller, “Openpsi: Realizing Dörner’s “PSI” Cognitive Model in the Opencog Integrative Agi Architecture”, Artificial General Intelligence – Lecture Notes in Computer Science() 6830, pp 212–221 (Springer, 2011).
BACK
43. A Augello, I Infantino, G Pilato, R Rizzo and F Vella, “Introducing a Creative Process on a Cognitive Architecture”, Biologically Inspired Cognitive Architectures 6, pp. 131-139 (2013).
BACK
44. Joscha Bach, Principles of Synthetic Intelligence PSI: an Architecture of Motivated Cognition (New York: Oxford University Press, 2009).
BACK
45. P K Mital, M Grierson, and T J Smith, “Corpus-Based Visual Synthesis: an Approach for Artistic Stylization”, ACM Applied Perception Symposium Proceedings (2013).
BACK
46. ibid.
BACK
47. A Chella, M Cossentino , S Gaglio and V Seidita, “A General Theoretical Framework for Designing Cognitive Architectures: Hybrid and Meta-Level Architectures for BICA”, Biologically Inspired Cognitive Architectures 2, pp. 100-108 (2012).
BACK
48. LeCun [3.]
BACK
49. Vaswani [6.]
BACK
50. Monika Schak and Alexander Geppert, “A Study on Catastrophic Forgetting in Deep LSTM Networks”, Artificial Neural Networks and Machine Learning – Lecture Notes in Computer Science() 11728, pp 714–728 (Springer, 2019).
BACK
51. A Dosovitskiy, L Beyer, A Kolesnikov, D Weissenborn, X Zhai, T Unterthiner, M Dehghani, M Minderer, G Heigold, S Gelly, J Uszkoreit and N Houlsby, “An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale”, arXiv preprint arXiv:2010.11929 (2020).
BACK
52. Ibid.
BACK
53. Laird, Rosenbloom and Newell [2.]
BACK
54. Ron Sun, “Can A Cognitive Architecture Fundamentally Enhance LLMs? Or Vice Versa?”, arXiv preprint arXiv:2401.10444 (2024)
BACK
55. T Sumers, S Yao, K Narasimhan and T Griffiths, “Cognitive Architectures for Language Agents”, arXiv preprint arXiv:2309.02427 (2023).
BACK
56. YS Xu, TJ Fu, HK Yang and CY Lee, “Dynamic Video Segmentation Network”, IEEE – Computer Vision and Pattern Recognition Conference Proceedings (2018).
BACK
57. X Zhang, Y Li , Y Han and J Wen, “AI video editing: A survey”, Preprints 2022, No. 2022010016 (2022).
BACK
58. K Zhang, G Riegler, N Snavely and V Koltun, “Nerf++: Analyzing and Improving Neural Radiance Fields”, arXiv preprint arXiv:2010.07492 (2020).
BACK
59. For recent findings on human and camera motion reconstruction from in-the-wild videos, see M Kocabas, Y Yuan, P Molchanov, Y Guo, M Black, O Hilliges, J Kautz and U Iqbal, “PACE: Human and Camera Motion Estimation from in-the-wild Videos”, 3DV – 3D Vision Conference Proceedings (IEEE, 2024).
BACK
60. Y Tonomura, A Akutsu, Y Taniguchi and G Suzuki, “Structured Video Computing”, IEEE Multimedia 1, No. 3, pp. 34-43 (1994).
BACK
61. Hirotada Ueda and Takafumi Miyatake, “Tree Structure Operation for Video Editing Utilizing Image Recognition Technology”, in INTERACT. – IFIP Human-Computer Interaction (Boston: Springer, 1997) pp 517–523.
BACK
62. Frank Nack and Alan Parkes, “The Application of Video Semantics and Theme Representation in Automated Video Editing”, Multimedia Tools and Applications 4, 57-83 (1997).
BACK
63. Frank Nack and Alan Parkes, “AUTEUR: The Creation of Humorous Scenes Using Automated Video Editing”, International Joint Conference on Artificial Intelligence – Workshop on AI and Entertainment Proceedings 21 (1995).
BACK
64. Retrieved from Nack and Parkes [63.]
BACK
65. B Aerts, T Goedemé and J Vennekens, “A Probabilistic Logic Programming Approach to Automatic Video Montage”, Frontiers in Artificial Intelligence and Applications 285, pp. 234-242 (2016).
BACK
66. Nuno Vasconcelos and Andrew Lippman, “Bayesian Modeling of Video Editing and Structure: Semantic Features for Video Summarization and Browsing”, ICIP – International Conference on Image Processing Proceedings (IEEE, 1998).
BACK
67. See the Kapwig Software <https://www.kapwing.com>, accessed 22 August 2024.
BACK
68. B Wang, Y Li, Z Lv, H Xia, Y Xu and R Sodhi, “LAVE: LLM-Powered Agent Assistance and Language Augmentation for Video Editing”, Intelligent User Interfaces Conference Proceedings, pp. 699 – 714 (2024).
BACK
69. H Ma, S Mahdizadehaghdam, B Wu et al. “Maskint: Video editing via interpolative non-autoregressive masked transformers”, CVF – Conference on Computer Vision and Pattern Recognition (IEEE, 2024).
BACK
70. P Sarmento, A Kumar, D Xie, CJ Carr, Z Zukowski. and M Barthet, “Shredgp: Guitarist Style-Conditioned Tablature Generation”, arXiv preprint arXiv:2307.05324 (2023).
BACK
71. R Lyle Skains, “Creative Practice as Research: Discourse on Methodology”, Media Practice and Education 19, No. 1, pp. 82-97 (2018).
BACK
72. X Chen, J Liu, Z Liu, L Wan, X Lan and N Zheng, “Knowledge Graph Enhancement for Fine-Grained Zero-Shot Learning on ImageNet21K”, IEEE Transactions on Circuits and Systems for Video Technology (2024).
BACK
73. L Gao, S Biderman, S Black, L Golding, T Hoppe, C Foster, J Phang, H He, A Thite, N Nabeshima, S Presser and C Leahy, “The pile: An 800gb dataset of diverse text for language modeling”, arXiv preprint arXiv:2101.00027 (2020).
BACK
74. A Karapantelakis, M Thakur, A Nikou, F Moradi, C Olrog and F Gaim, “Using Large Language Models to Understand Telecom Standards”, ICMLCN – International Conference on Machine Learning for Communication and Networking Proceedings, pp. 440-446 (IEEE, 2024).
BACK
75. Dosovitskiy et al. [51.]
BACK
76. Pasquier, Philippe, et al. “An introduction to Musical Metacreation”, Computers in Entertainment 14, No. 2, pp. 1-14 (2017).
BACK
77. B Wang, Y Li, Z Lv, H Xia, Y Xu and R Sodhi [68.]
BACK
78. TJ Fu; X Wang; S Grafton; M Eckstein and W Wang, “M3l: Language-Based Video Editing Via Multi-Modal Multi-Level Transformers”, CVF – Computer Vision and Pattern Recognition Conference Proceedings (IEEE, 2022).
BACK
79. OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal et al., “GPT-4 Technical Report”, arXiv preprint arXiv:2303.08774 (2023).
BACK
80. Sumers et al. [55.]
BACK
81. Doulamis et al. [37.]
BACK
82. H Li, Y Ma, and J Principe [41.]
BACK
83. Jeffrey Zacks, Flicker: Your Brain on Movies (Oxford Univ. Press, 2015).
BACK
84. Alexei V Samsonovich, “Emotional Biologically Inspired Cognitive Architecture”, Biologically Inspired Cognitive Architectures 6, pp. 109-125 (2013).
BACK
ABOUT THE AUTHORS, REVIEWERS AND EDITOR
Authors
Luís Arandas > University of Porto
Researcher and designer focusing on algorithmic systems, digital tools and experimental media. His work combines creative practice with critical inquiry into computational methods, exploring how code, automation and generative processes influence interactive forms and emergent audiovisual expression in contemporary digital culture.
Pedro Sarmento > Queen Mary University of London
Musician and media artist working across guitar performance, computer-mediated music and creative coding. His projects span sound experimentation, interdisciplinary collaboration and real-time systems, investigating how technology can extend musical practice and shape new modes of performance, composition and interactive artistic production.
Mick Grierson > University of the Arts London
Professor of Computer Science and co-founder of the UAL Creative Computing Institute. His research bridges creative AI, interactive media and machine learning, contributing foundational work in early deep-learning systems for audio, video and performance. He collaborates widely with cultural institutions and industry on innovation in computational creativity.
Miguel Carvalhais > i2ADS / University of Porto
Designer, musician and researcher whose work spans computational art, sound and design. As professor and director of the Faculty of Fine Arts at the University of Porto, he integrates artistic experimentation with analytical inquiry, exploring how digital systems shape aesthetic processes, performance and contemporary creative practice.
Reviewers
Kate Sicchio > Virginia Commonwealth University
Artist, choreographer and researcher exploring how movement, code and embodiment intersect in live performance. As Assistant Professor at Virginia Commonwealth University, she connects creative practice with research in interactivity, dance technologies and algorithmic performance, examining how bodies and systems co-construct expressive and computational forms.
Nuno Correia > Tallinn University
Researcher and media artist whose work spans sound, multisensory experience and embodied interaction. As Associate Professor in Digital Transformation at Tallinn University, he coordinates Creative Europe projects linking dance, technology and AI, investigating how audiovisual systems and interactive media shape contemporary digital culture and artistic practice.
Editor
Adriana Sá > CICANT / Lusófona University Artist and researcher working at the intersection of sound, performance and interactive media. She investigates perception, embodiment and interface design, integrating intuitive artistic practice with rigorous research. Her work examines how interfaces can function simultaneously as expressive systems and critical tools for exploring technologically mediated experience.
Continue with LIVE INTERFACES Volume 2: