AN INTRODUCTION
I recently came across this blog post, on Hackaday, titled “AI is Only Coming for Fun Jobs” (1). The title says it all – creativity is being superseded by artificial intelligence, drawing upon a massive database to assemble appealing images, text, and sound “assets” in video games, pushing the human creator to the side-lines. So, what can we mere mortal programmers do to provide value to our creative foundation?
From the perspective of a programmer, I call it speculative programming. I do not believe that an A.I. can be ‘speculative’. While it might be able to spit out some code for finding a path through a forest, it cannot create behaviours based on a ‘personality’ encoded into a Non-Player Character (NPC). Can it even understand that as a prompt? Will an A.I. ever have the capacity to just ‘go for it’ and explore a solution, something not built into its training?
In this research, I am using well-established algorithms, implemented in C# and represented in Unity. Vital to the distinction between an A.I. and a human, I’m employing intuition, and perhaps even that complicated word, art, to create a system that enables fungible interpersonal relationships between NPCs and Player/Observers (humans) in real-time – using tiny neural networks clustered in a buckyball configuration, which I am calling a tinyNet.
‘Buckyball’ is the nickname for a molecule named in honor of architect R. Buckminster Fuller, due to its resemblance to his geodesic dome structures. Connecting 60 carbon atoms, its structure is made up of 20 hexagons and 12 pentagons, mirroring the pattern found in geodesic domes – also known as a dodecahedron. See Video 1:
Video 1: Screen capture from the “big” tinyNet in action. John Klima, 2025.
Over the course of this investigation, I kept returning to the notion that a look-up table (LUT) can be encoded as a neural network, such that a neural network can “know” that 3 + 4 = 7 without performing any math. A LUT is essentially a spreadsheet where one looks at the cell that is in row 3, and in column 6, to arrive at a return value. If LUT is replaced with a neural network, it implies that the network can be trained to “re-learn” that 3 + 4 = 8. In other words, the tinyNet can change the rules of the game – training overrides encoded logic.
To investigate this, I started with the most simple game: Rock Paper Scissors. We all know the rules of this game, and the results can be made into a simple 3×3 look-up matrix. But the fact is, every individual will have a proclivity to choose rock, or paper, or scissors each time the game is played. Given two “individuals” on first encounter, the normal rules apply. But if these individuals have several encounters, can they not predict the other’s behaviour? Can they not both change the rules to their favour? This is not a prediction so much as it is simply applying a different set of rules when Fred encounters Jane, and when Jane encounters Julia.
The research brings up another issue. There exists this thing I like to call the “crisis of representation”. How does one demonstrate the underlying concept of the algorithm that is making these decisions? Sadly, video game combat situations seem to be the clearest way to represent cause and effect in a person-to-person encounter. I can easily represent through animations and other means that rock beats scissors. But how does one represent, over time, that one person doesn’t like this other person, and why? Or, indeed, is perhaps in love with that other person, and why? Without having a huge repository of gestures and animations that can clearly demonstrate this cause and effect, we have a crisis, and at best we have a gigantic finite state machine (FSM) that is totally predictable regardless of its depth, and very cumbersome to maintain and expand.
Combat scenarios unfortunately are the clearest form of person-to-person relationships that one can represent in identifiable terms, without using dialogue. There have been great advances in using Large Language Models (LLMs) to create dynamic exchanges in computer-human interactions, primarily around dialogue systems (2). But very little around recognisable physical behaviours, let’s say “body language”, to convey emotion, sympathy, empathy, or hatred.
However, I propose that a hybrid tiny network topology is a step in the right direction, as it has – inherent to its structure – the ability to adapt, and feed fuzzy numbers to a blending of representations in a system designed to accommodate them. A mixture of gestures that can represent a range of emotional responses emergent from the interaction between one character and another, or between the Player (primary agent) and an NPC (a secondary agent); using sound, animation blending, lighting techniques, what have you. A tinyNet is adaptable to every representational challenge that I can imagine. The truly interesting aspect of this is that the same network code, applied to multiple tasks, can easily make for those tasks to inform each other through their inputs and outputs.
I am not sure exactly what I’m going to “get” from this, I’m just working intuitively with the idea in the back of my head that I want to make an NPC “personality” that changes through time, via Player choices. My NPC is not the same as your NPC, even if they are both named “Fred”. Having worked with neural networks for more than 20 years, I simply have this intuitive feeling that I can use them to achieve my goals. That intuitive feeling is not something that an AI possesses, it is fully in the human domain.
THE NON-MATH
I like to use this term, non-math, to describe the purpose of the network. I use simple math problems to demonstrate that the network is returning “valid” results, but can equally be retrained to produce a different result: 2+3=5 is valid, but 2+3 could also return 23 (the numeric combination).
Though there is a wealth of complex mathematics going on under the hood and I am working numerically, the numbers are symbolic. I use the sigmoid function (a mathematical function that maps any real-valued number to a value between 0 and 1) but I’d be hard pressed to “solve it for x”. I don’t need to, that’s what the computer is for. I’m using numbers but they are simply symbols.
Again, to be clear, input one = 3, input two = 4, output = 7. It did not add the numbers, it simply knew that 3 and 4 is 7. You can almost think of it visually, or in terms of symbols. You have this scratch in the sand, a squiggle that looks like 3, and another that looks like 4. If you combine those two squiggles, don’t they kind of look like 7? Does not 3 combined with 2 kind of look like 5? Is this not what we do in our deep head when asked what 3 plus 2 equals? We know the answer, as long as the equation isn’t too complicated.
Computers count beans. Do we count 3 beans and add 2 beans to them to arrive at 5 beans? No!!! We consider the ‘3’ symbol and combine it with the ‘2’ symbol, to arrive at the ‘5’ symbol. It might as well be 6: the 3 squiggle and the 2 squiggle, when combined, does it not really look like the 6 squiggle? Or maybe, does it look more like the 5 squiggle? I can start with the assumption that 3 + 2 is most likely the 5 squiggle. Subsequently, if I pass the 5 squiggle output and a 3 squiggle output to another node, it will almost certainly arrive at the 8 squiggle. Does 3 plus 5 not kind of look like 8? This is essentially how a neural network functions.
We use beans as a method to confirm our symbolic assumptions. Thankfully, in Principia Mathematica Bertrand Russell proved through logic that 1 + 1 = 2 (3), something mathematicians were struggling with for hundreds of years. Of course, we intuitively know that if I have three beans, then I get two more beans, I have 5 beans; but until Russel, there was no proof of it!
THE NEURAL NETWORK’S “WORKINGS”
I will be making in-game representations of the network using Unity – a well-known digital platform for the creation of video games – thus I will be coding in the C# programming language. I am using my own variation on what is discussed in the section “Coding Neural Network Back-Propagation Using C#” from the Visual Studio Magazine:
“Back-propagation is based on calculus partial derivatives. Each weight and bias value has an associated partial derivative. You can think of a partial derivative as a value that contains information about how much, and in what direction, a weight value must be adjusted to reduce error. The collection of all partial derivatives is called a gradient. However, for simplicity, each partial derivative is commonly just called a gradient.” (4)
I understand more or less what that means, but I don’t really care, as long as it works. I am not trying to reinvent the wheel; I’m modifying that example heavily to suit my needs. For example, none of it is now hard-coded: I have made public variables in a wrapper class so that I can fiddle with it in the Unity inspector, and am saving thousands of small “weight files” – essentially what the tinyNet knows at this given moment, given its training.
THE SIGMOID FUNCTION
At the root of a neural network is a sigmoid function. It is what creates the gradients mentioned above. A sigmoid function refers specifically to a function whose graph follows the logistic function (5). It is defined by the formula in Fig. 1:

Figure 1: The sigmoid function (could not resist an equation).
The best way I can think of it is: a ball rolling down a hill into a valley and up the other side, and back again. It will eventually find a resting place, the “answer”. This also feeds into a programming technique I have used countless times, error correction. Is it too much? Cut it in half. Is it too little, double it, until you have a satisfying result.
START THE BUILD
The number of inputs is arbitrary. Eventually I arrived at 2 inputs, and I found I get great accuracy if each tinyNet has only one output (which of course could go to many other inputs, not just one). There are simply two values that form a question, and a tinyNet will produce one output, the answer.
By taking the code from Visual Studio Magazine (6) and making it “Unity friendly”, I have this rough interface with access to the various parameters I fiddle with to achieve a result (7). Fig. 2 shows the parameters used to train the network:
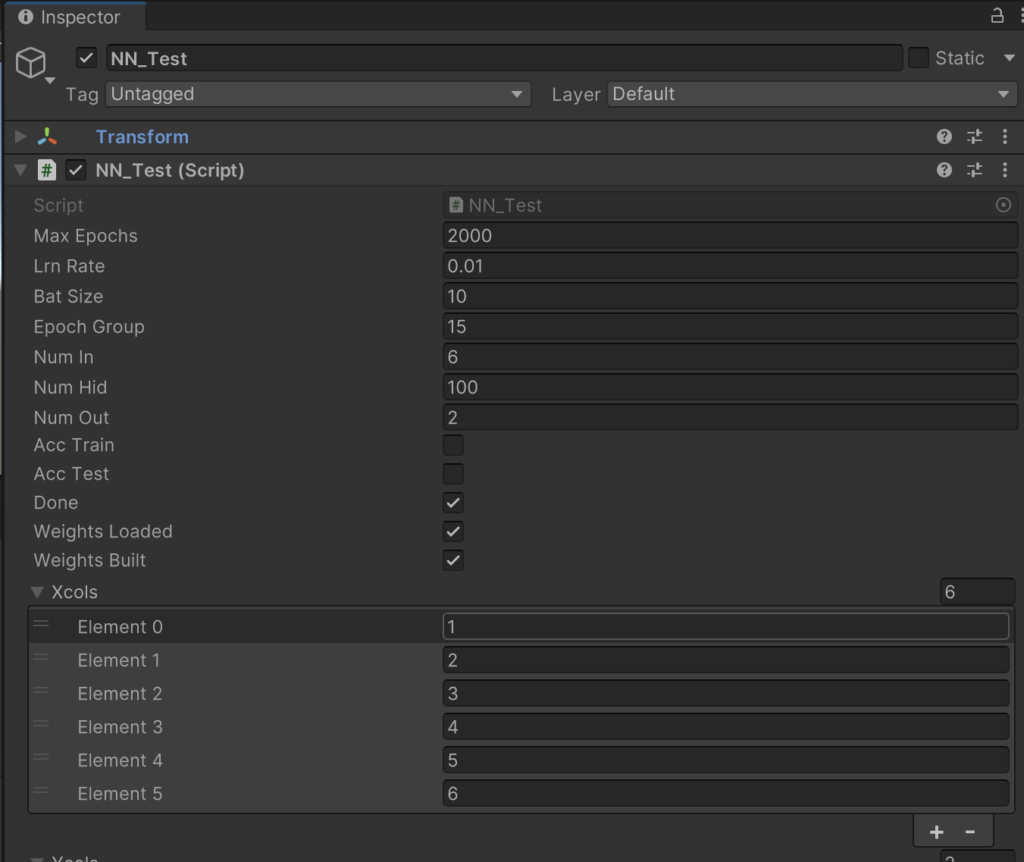
Figure 2: Initial single node network, encoded in the Unity Inspector.
These parameters are totally intuitive, you do trial and error to then see if the question is answered to your satisfaction. Once it seems like a good set, you leave it. These essentially become constants.
After making the first tinyNet, exposed above, I thought about the interconnection architecture to accommodate many, and chose to implement a scripted buckyball – a dodecahedron – to build and connect the tinyNets. Fig. 3 shows how this looks like:

Figure 3: The buckyball topology.
In this topology there are simply two input nodes and one output node at each intersection; each output becomes an input to the next node, forming the larger buckyball. But it can also regress, such that each node is being informed from yet another buckyball topology, and on, and on.
For a simple example, one could train the tinyNets to “know” math, 2+3=5:
| input 1 = 2 | input 2 = 3 | output = 5 |
And output = 5 becomes input 1 to another tinyNet, performing another task, perhaps 5 + 3 = 8.
A simple “add” network would be easy to train and test, just to prove that the idea actually works. It is not performing arithmetic; it simply knows the answer is 5. It is not “adding” anything directly, though there is plenty of mathematics happening underneath, within that neural network. I chose a buckyball because they are just cool, but any polyhedron could work. Just so it is as clear as milk, no arithmetic would occur inside the balls, they would simply “know” the answer.
At this point, it is all about the questions I ask. I am converting integers – whole numbers including positive numbers, negative numbers and zero – to floating point decimals because floats are more appropriate to the network architecture, at least from my first glance. After initial training, 0.2 + 0.3 = 0.4999987 as you can see in Fig. 4:

Figure 4: 2 + 3 = 5, more or less.
Probably a floating-point precision rounding error you ask? No: the neural network does not produce the “exact” answer. A double precision floating point (that is a 64-bit format for representing real numbers in computer systems) would just have more 9’s in it, I would expect. Specifically germane to my intended use, the precision shown above is completely unnecessary. Close enough for horseshoes and hand grenades (and government work). Any more accuracy than 0.499 could indeed be undesirable, as unpredictability and organic growth are the core principles I wish to explore.
My neural network uses values between 0.0 and 1.0, or -1.0 to 1.0 to be precise. But we might as well be positive about life, and divide by two. If I want to represent something called “middle”, that would be 0.5. It could not be easier to understand, and it avoids the issue of crossing zero, or indeed somehow resulting in zero, which if used in an equation can wreak havoc. Math forbids I divide by zero, or pass it, or a negative number to a square root function.
I trained it on 0.2, 0.3, 0.5. Thus 0.18 and 0.25 should result in something close to the “truth”. See Fig. 5:

Figure 5: 0.18 and 0.25 results in 0.4999022.
The result is 0.4999022, nearly 0.5. Not as precise as the previous run on “perfect” input data. Not bad at all, though 0.43 would be the exact result.
There is a big difference between 4999987 and 4999022 if one only looks at the divergent decimals, as if they were integers. Subtract them and you get 965 divergent to be exact. That is useful.
I trained the network only upon 0.2 and 0.3 outputs 0.5 and yet it returns a semi-valid prediction for significantly “flawed” input. For example, 1.5 and 2.5 does not equal 4 (in math); it equals 5 because that is the closest pattern match according to the training. I suppose that’s the point, how can it handle flawed input. Which begs the question, why call it flawed?
So now I will add the training for precisely 0.18, 0.25, 0.43 on top of the previous training set. Let’s see what happens (Fig. 6).
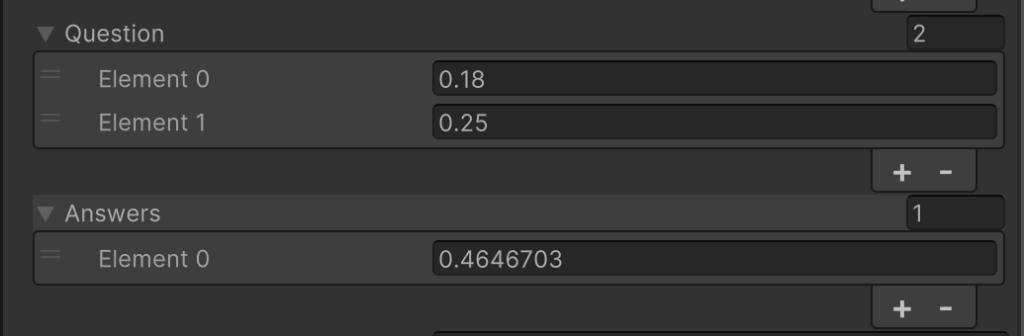
Figure 6: Adding the training for precisely 0.18, 0.25, 0.43 on top of the previous training set results in 0.4646704.
Much closer to “truth” – but you see, 0.2, 0.3, 0.5 has an influence on 0.18, 0.25, 0.43. I find this fascinating. Keep in mind that I could train 0.2, 0.3 to return 0.23 – it’s whatever I want it to output, based on input.
Let’s see what happens if I retain 0.18, 0.25, 0.43 and train 0.2, 0.3, 0.23 on top (Fig. 7).
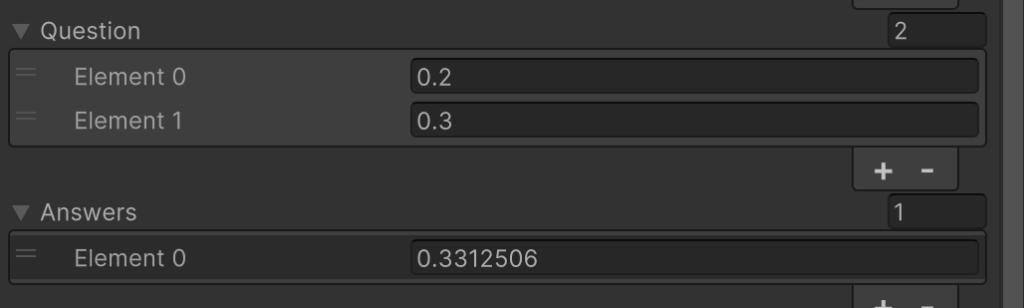
Figure 7: Adding 0.2 and 0.3 trained to equal 0.23 on top of the previous training set results in 0.3312506.
If I want this to be more accurate, I need to train more on 0.2, 0.3, 0.23 – lets see (Fig. 8)…

Figure 8: Adding 0.2 and 0.3 trained to equal 0.23 on top of the previous training set results now in 0.2812851, converging on the “truth”.
Much closer to 0.23. These are just amazing fun toys to play with. As you see, 2 + 3 no longer equals 5: the resulting value is close to the combination of the individual integers as singular representations, or symbols, rather than a mathematical equation. The same network retrained to do something else, at run-time.
The point now is to solve a game A.I. problem, and my goal is to create character personality that can change over time, without having to build a gigantic finite state machine.
I now have it instancing and running on each node in my buckyball (8). Final code tasks are to connect the output of one node as the input of another. Basically, connect the dots, then I’ll train it to run trivial additions, where each node “knows” the answer to 2+2 etc…, rather than calculate it. Then I’ll test and confirm it can handle a series of addition problems, or “questions.” Then I’ll figure out what to do with it and re-train it accordingly, knowing that it is working well enough based on these simple math tests, I can trust that if I apply a different desire, it will function as long as I can define my desire.
RUBBER STARTS TO MEET THE ROAD
Okay, now is the time to do some “real” network training. When I made the first network I trained it on 0.2, 0.3, 0.5 aka 2 + 3 = 5. Sure enough, I got 0.499999 as a result. So, there happen to be 20 nodes, or vertexes, in a buckyball. And every combination of integers 1 to 5, added together, obtain 20 combinations in each digit order. For example:
| 5 + 0 = 5 | 0 + 5 = 5 | 1 + 4 = 5 | 4 + 1 = 5 |
Etc… All the way down to 0 + 1 = 1, 1 + 0 = 1.
I have 20 nodes in one buckyball, and each node can start with a “hard training” on each of those 20 combinations! See Fig. 9. What luck, or intuition.


Figure 9: Top: Combinations of integers, hand-written notes on paper by John Klima, 2025. And then, bottom, the same thinking ‘downgraded’ into a more readable format.
If I connect a node that returns 2 as the answer, and a node that returns 3 as an answer, and send those as inputs to a node that “does” 2 + 3 = 5, I should get a perfect answer. I have quantifiable confirmation that the entire structure is valid. Pure magic! I can now create a complete buckyball structure assuming this simple “proof”; one can replace the numbers with symbols, and at the start, have a predictable result. But then the network can “learn” from experience that 2 + 3 = 6.
My whole point with this endeavour is to see if clustered, tiny neural networks can replace massive finite state machines for character behaviour. No more, no less, I am just asking the question. I think they can. I did not find anybody who has been working on this, and that surprises me as I was already looking at this twenty years ago – when machines were slow, by today’s standards, and A.I. was relatively new.
I will start simply, featuring two NPCs battling in Rock Paper Scissors. Each NPC prefers one of those options. So, can one NPC be retrained to predict what the other might select, consider the other’s preference, and modify his own selection to achieve success more often than not? And then, what happens when this trained NPC encounters another with a very different tendency? Through training, it obtains a tendency that can then be exploited by another who trained to defeat it. If I did add a third input node, could the one NPC be trained to learn three different opponents?
The next exciting investigation, now, is to train a node in my neural network for one NPC to detect the tendency of the other in unsupervised learning mode (a type of machine learning that analyses unlabeled data to find hidden patterns and structures without explicit guidance, or labeled data) and win more often than not.
ROCK PAPER SCISSORS
I am intrigued by the idea of developing intelligent NPC behaviours where, instead of using a state machine, a neural network is utilised to train a group of NPCs that all have the same foundational logic, resulting in diverse behaviours. In 2006, for my Master’s thesis, I developed a basic backpropagation neural network – an algorithm for supervised learning. This network was capable of being trained on an input pattern to dictate a character animation. It was unexpectedly effective and could be retrained to obtain a different outcome while the simulation was in progress. Therefore, it appeared clear that a single NPC could improve as an opponent (considering a combat style game), or evolve into either an ally or an enemy, as the game progressed. The same NPC in my game might appear quite different from the same NPC in your game.
I moved forward with training a network to play Scissor, Paper, Rock (apologies for my order, it is how I encoded it). I trained a network to know what it “should have” done, not what it “should do”. For example, if I play Scissors and my opponent played Rock, I should have played Paper. It does not change the fact that I played Scissors. I discovered some very interesting properties of the network.
I configured a net consisting of two input nodes – what I played, what my opponent played, and one output being what I “should” have played. I encoded 0.0 == scissors, 0.1 == paper, 0.2 == rock. A logical place to start if one desires to ascribe meaning to what are essentially integer values in an enumeration. I employed a hidden layer of 64 nodes (hidden layers are the intermediary stages between input and output in a neural network), because that worked well with the simple integer math problem described above (3 + 4 = 7).
It failed miserably! So I went to the cafe and gave it a think. I arrived at two suppositions. Firstly, the numeric difference in my encoding was not broad enough to produce high resolution results. Secondly, for a problem that has only six permutations, maybe I want just six hidden nodes, rather than sixty-four. The approach to configuring a neural network for optimal results is not really a science. It is often simply an intuitive, trial and error process.
After juggling with some numbers here and there, I arrived at 0.25, 0.5, 1.0 to equal Rock Paper Scissors respectively. I came up with this training set of all permutations:
| 0.25, 0.5, 0.25 | 0.25, 1.0, 0.5 | 0.5, 0.25, 1.0 | 0.5, 1.0, 0.5 | 1.0, 0.25, 1.0 | 1.0, 0.5, 0.25 |
Thus, if I play something around 0.25 and my opponent plays something around 0.5, I should have played something around 0.25, which I did – all good, first line in the set. I played Scissors (0.25), opponent played Paper (0.5), so Scissors is correct (0.25). If I played Scissors (0.25), opponent played Rock (1.0), I should have played Paper (0.5) – second line in the set.
Keep in mind that these are not absolute values. Think of it as being “Scissors Like” vs. “Rock Like”. Meaning that “Paper Like” is what I should have played. That is when I realised I needed threshold values, with cut-offs. To arrive at definitive literal representations, these will be:
| < 0.26 is Scissors | < 0.6 && > 0.26 is Paper | < 1.0 && > 0.6 is Rock |
However, if say, an animation blending system was passed the actual values, it could directly modulate its “mixing” according to those values. The same would of course apply to audio generation, and indeed any mechanism of representation that is looking for floating point values in this general range. Trust me, there are many of them.
I trained my system for 12000 epochs (in an epoch, we use all of the data exactly once); that is a huge number of epochs but the set is so small it took no time at all. Then I started to ask the questions and got fine results throughout. All answers were well within the correct threshold values (see Fig. 10).

Figure 10: Result output from an animation blending system trained on 12000 epochs.
I love this idea that I am “kinda sorta Rock”, my opponent is “kinda sorta Scissors”, therefore I “kinda sorta Win”.
Assuming my opponent prefers scissors, paper, or rock, and that I have gathered the appropriate responses for this scenario, I can train my tinyNet to indicate that against this opponent I should choose this option. That generates habits in me, leading to situations where, upon facing another rival, they possess an equal chance to learn my habits, which in turn fosters habits of their own. When this adversary confronts my initial opponent, it will modify that opponent’s behaviour so that the next time I compete against that initial opponent, it has adjusted its strategy, and so on.
The point here is not to use this system to play Rock Paper Scissors, but to use it as a clear and understandable indication that the tinyNet functions, and can be trained and re-trained to achieve a variety of results, and “solve” a variety of problems. See Video 2:
Video 2: Demonstration of the tinyNet in its simplest form, by using the principles from Rock Paper Scissors applied to a Ninjas’ combat.
To summarise, I have built a neural network that “knows” the outcome of the game, not from a look-up table, rather it simply spits out the result of a play, just like the previous math example “knows” 2+3=5 without doing math. The interesting thing here is that over time the tinyNet can change the rules of the game such that rock can defeat paper. Changing the rules without changing the code is somewhat mind-blowing, and indeed my goal.
LET’S JOUST!
Let’s now expand the problem to something more complex. I chose the Jousting Matrix from the original Chainmail ruleset (9). See Fig. 11):

Figure 11: My original Chainmail Joust Matrix.
If one has a long look at this, each Player chooses an aim point and a defensive posture, and based on the matrix, a resolution is obtained. However, is this not just a more complex manifestation of Rock Paper Scissors? Yes and no. Read the post “Strategy on the Jousting Matrix” by Stephen Wendell (10).
And there is a SubReddit (meaning a forum dedicated to a specific topic on the website Reddit) discussing “strategy” behind the Joust matrix (11). Believe it or not, there is one. After one joust, in the next joust a Player may be forced to assume a defensive position for that next round, thus the other Player knows how to win that next round because he knows what the other Player must do.
All that having been said, first, can I design and train a neural network to “know” the matrix result (thus it could change the rules)? And second, can I design and train another network to understand the Joust strategy described above? Then, I think, I’m starting to get somewhere (see Video 3).
I hesitate to use combat scenarios, as the aim is to be more general purpose. But the fact is, combat relates to the majority of games in one way or another. It is easy to represent combat with clearly indicative animations, it is easy to comprehend the cause and effect relationship, and it is easily quantifiable. Something more qualitative like dialogue, or personality, is the goal – but it is extremely more challenging to represent.
PERSONALITY
To actually address the notion of “personality” beyond combat, I began to investigate research outside of the computational realm, though some of it has been integrated by other game researchers. At the top of the list is the “5 Factor Model” of personality – here referenced in terms of game research (12), but widely adopted in a variety of fields:
openness
conscientiousness
extraversion
agreeableness
neuroticism
I came across “Maslow’s Hierarchy of Needs”(13), which includes the ‘needs’ listed below:
air
food
drink
shelter
clothing
warmth
sex
sleep
order
predictability
control
friendship
intimacy
trust
acceptance
receiving affection
giving affection
love
dignity
achievement
mastery
independence
curiosity
exploration
greed
lust
power
fame
fortune
That is quite an extensive list of traits that must be encoded in a meaningful way such that an individual NPC can demonstrate these traits, and such that the Player/Observer can identify them.
We can also look at the basic set of traits from the original publication of the Dungeons & Dragons rule-set:
strength
intelligence
wisdom
dexterity
constitution
charisma
How can these lists be integrated and represented on screen? I think to do that one simply starts to assign core values. One can almost think about them as “genes” first to the 5 point factors, then to the rather exhaustive list of basic needs. How much does strength contribute to food? How much does any of them contribute to any other?
That would depend of course on the specifics of an encounter. I need a lot of strength to take down a woolly mammoth, less so for a rat. Though perhaps I need more intelligence for the rat. Then what happens when strength and intelligence are combined against the woolly mammoth? Species extinction, as many investigators believe. Man became so good at killing woolly mammoths in great quantity (drive them over a cliff), that it did not take long before there were no woolly mammoths left.
I think the 5 point factor needs to be added to the classic Dungeons & Dragons (D&D) traits to arrive at a baseline for situational evaluation of the larger list of human “needs”. Again, we are talking about some form of a look-up table, but if any look-up table can be expressed within a neural network, the results become fungible, individual, and hard to predict.
Obvious in D&D if the NPC has low strength and high intelligence, he/she will cast a spell and not swing a sword. However, if the caster is out of mana, and all they have remaining is their dagger, dagger it is, or surrender, or run away. Can we then add emotions, or mental states, such as below:
openness
conscientiousness
extraversion
agreeableness
neuroticism
And then, creating and manipulating that results into representations in the game:
patrol a path
attack a Player:
with weapon?
with spell?
with other?
initiate dialogue:
male/male
male/female
female/female
flee:
orderly
disorderly
take cover:
where?
hide:
where?
sneak
Etc…
An agent has goals – survive, become rich, kill the murderers of his parents.
To survive, the strategy is to stay away from danger, and drink/ eat regularly.
To drink regularly, the agent’s tactic may be to stay close to a river.
I have the combat working all nicely; when 2 characters enter a volume (box collider), they slug it out. I call it an Encounter. But I wanted to make it OOP (Object Oriented Programming) such that the encounter can marshal a fight, a conversation, kissing, whatever. The volume has a trigger that adds whoever enters the volume to the Encounter, based on an abstract class called “Participant”. The trigger collider “other” has a concrete class called PlayerParticipant. Though Encounter has a list of base “Participants” it is happy to add “PlayerParticipant” to its list. It could be “PuppyDogParticipant” – it doesn’t care.
Once enough participants are part of the encounter, off it goes and resolves it. So, puppy does what it does, and Player does what it does, and the two know everything about each other. So, a Player and a Puppy will resolve what they have in common, and a Puppy and a Puppy will resolve what they have in common, which will certainly be different than Player vs. Puppy.
FEUDAL JAPAN
It was finally time to apply some of what was discussed above, in a more social context. I am no modeler nor animator, and thanks to Synty (14) for creating asset packs for a few bucks, and Mixamo (15) for providing a range of compatible animations for free. I am fond of the Samurai assets from Synty and arrived at this look-up table as the basis of initial reactions based on character type (see Fig. 12). When a “Samurai Grunt” (Sam Grnt) encounters a Geisha, he will flirt. When the Geisha encounters a Grunt, she will ignore him, at least as first encounters go. As with everything thus far discussed, this relationship will change over time.

Figure 12: The reaction look-up table used as the basis of initial reactions, programmed in terms of my tinyNet.
LOOMING DEADLINES
With this journal’s submission deadline around the corner, I needed to wrap up at least one loose end, with a demonstration of how a character can learn. There is still much, much to do, and this research will continue far into the future. For the demonstration, I have used a 20-node network that is trained on two parameters to choose an animation, and started playing with numbers (Video 4). Then I simply made the rule that a kick beats a punch, and that the puncher should kick instead (Video 5). It is a bit more generalised in that if I lose, do what the other guy is doing.
CONCLUSION
I have shown how the tinyNet can replace explicit arithmetic in a narrow mapping task. Given the 2+3=5 “pattern” it knows the answer is 5, without counting any beans. I have also shown that a variety of “combat matrices” can be replaced with a neural network, such that the rules of the game can change, in response to tendencies in a specific opponent. These fuzzy neural networks can then drive representation systems – animation, audio, what have you. I also created a simple fitness algorithm that retrains a character at run-time to essentially mimic what another character is doing. There is still a great deal of research I will continue to “code up” as I feel I am barely half-way to my goal. I will need to build an interface to facilitate a “designer” to easily create the behaviours that fit within the game design. Lastly, I will need a game design that best demonstrates the potentials of the system.
REFERENCES AND NOTES
1. Bryan Cockfield, “A.I. Is Only Coming For Fun Jobs”, Hackaday.com, 5 July 2025, <https://hackaday.com/2025/07/05/ai-is-only-coming-for-fun-jobs>, accessed December 2025.
BACK
2. See, for example, Samuel R Cox and Wei T Ooi, “Conversational Interactions with NPCs in LLM-Driven Gaming: Guidelines from a Content Analysis of Player Feedback”, in Chatbot Research and Design: Conversations 2023 (Cham: Springer, 2024) pp. 167–184.
BACK
3. Alfred N Whitehead and Bertrand Russell, Principia Mathematica, 3 vols. (Cambridge: Cambridge University Press, 1910–1913).
BACK
4. James McCaffrey, “Coding Neural Network Back-Propagation Using C#”, Visual Studio Magazine, 14 April 2015, <https://visualstudiomagazine.com/articles/2015/04/01/back-propagation-using-c.aspx>, accessed December 2025.
BACK
5. A graph that follows the logistic function has an S-shape, called a sigmoid curve. This curve represents a growth pattern that initially increases rapidly, then slows down as it approaches a maximum limit.
BACK
6. See McCaffrey (2015) [4.]
BACK
7. If the reader wants to know more about the various parameters I fiddle with using Unity, refer to McCaffrey (2015) [4.]
BACK
8. An instance is a concrete implementation of an abstract concept. We have the concept of “cat,” and then there exists this actual cat.
BACK
9. Gary Gygax and Jeff Perren, Chainmail: Rules for Medieval Miniatures, 3rd ed. (Lake Geneva, WI: TSR, 1975). Published under the banner of Tactical Studies Rules (TSR), this book served as a foundational rule set for the development of Dungeons & Dragons.
BACK
10. Stephen Wendell, “Strategy on the Jousting Matrix”, 28 July 2021, <https://www.donjonlands.com/2021/07/strategy-on-the-jousting-matrix> accessed December 2025.
BACK
11. Retrieved from a community platform: “Chainmail Jousting Rules in D&D?”, 2023, <https://www.reddit.com/r/osr/comments/16sa65l/chainmail_jousting_rules_in_dd>, accessed December 2025.
BACK
12. Found in this blog: Saul McLeod, “Maslow’s Hierarchy Of Needs”, Simply Psychology, 3 August 2025, <https://www.simplypsychology.org/maslow.html>, accessed December 2025.
BACK
13. Found in this blog: Annabelle Lim, “Big Five Personality Traits: The 5-Factor Model Of Personality”, Simply Psychology, 20 March 2025, <https://www.simplypsychology.org/big-five-personality.html>, accessed December 2025.
BACK
14. See <https://syntystore.com>, accessed December 2025.
BACK
15. See <https://www.mixamo.com>, accessed December 2025.
BACK
ABOUT THE AUTHOR, REVIEWERS AND EDITOR
Author
John Klima > Noroff University
Artist, musician and engineer working with custom electronics, software and electro-mechanical systems that interconnect virtual and physical worlds. His practice spans international exhibitions and collaborations within the game industry, alongside teaching roles in digital media and game design that bridge technical development with creative experimentation.
Reviewers
Composer, researcher and educator working across electroacoustic music, interactive installations and sound spatialisation. As Associate Professor and Vice-President for Artistic Research at ESMAE, he develops projects that integrate composition, technological experimentation and performance, contributing to contemporary discourse on digital creativity and embodied musical practice.
Rui Antunes > CICANT / Lusófona University
Artist and researcher whose work spans digital arts, live audiovisual performance and human–machine interaction. He creates installations and performances exploring embodiment, experiential design and computational media, integrating sound, image and interface technologies to examine how artistic practice responds to shifting modes of technological engagement and perception.
Editor
Adriana Sá > CICANT / Lusófona University
Artist and researcher working at the intersection of sound, performance and interactive media. She investigates perception, embodiment and interface design, integrating intuitive artistic practice with rigorous research. Her work examines how interfaces can function simultaneously as expressive systems and critical tools for exploring technologically mediated experience.
Continue with LIVE INTERFACES Volume 3: